The Python programming language has many libraries that can read, write, and manipulate CSV files. Python’s built-in csv module is one such library. It can be used to read or write the contents of a CSV file or to parse it into individual strings, numbers, etc.
When it comes to converting CSV to an Excel file, we must use an external module that let us work with Excel files (xlsx). There are few such libraries to choose from.
For this article, we are going to use the xlsxwriter module.
Create and read CSV files
This example code creates a CSV file with a list of popular writers (3 male and 3 female writers).
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import csv with open('writers.csv', 'w', newline='') as file: writer = csv.writer(file) writer.writerow(["#", "Name", "Book", "Gender"]) writer.writerow([1, "Agatha Christie", "Murder on the Orient Express", "Female"]) writer.writerow([2, "J. K. Rowling", "Harry Potter", "Female"]) writer.writerow([3, "J. R. R. Tolkien", "Lord of the Rings", "Male"]) writer.writerow([4, "Stephen King", "The Shining", "Male"]) writer.writerow([5, "Danielle Steel", "Invisible", "Female"]) writer.writerow([6, "William Shakespeare", "Hamlet", "Male"]) |
The file is written at the default file location. If you open it with a notepad, it’s going to look like this:
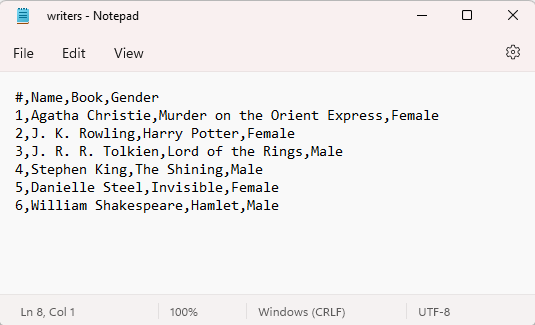
Read CSV
This code reads the CSV file and prints the result on the console.
|
1 2 3 4 5 6 7 8 |
import csv file = open("writers.csv") csvreader = csv.reader(file) for row in csvreader: print(row) file.close() |
Create Excel Sheet
Now, let’s create an Excel sheet.
|
1 2 3 4 5 6 |
import xlsxwriter workbook = xlsxwriter.Workbook('writers.xlsx') worksheet1 = workbook.add_worksheet('Male') worksheet2 = workbook.add_worksheet('Female') workbook.close() |
This code creates an Excel file called writers.xslx with two worksheets: Male and Female.
At the end of the code, there is the close function. Without it, the file won’t be created.
Convert a single CSV file to multiple sheets
In this part, we are going to read CSV and write everything into an Excel file. Let’s start from the header. There is only one CSV file, so we need to take the header and write it twice into both Excel worksheets.
|
1 2 3 |
for index in range(len(header)): worksheet1.write(0, index, header[index]) worksheet2.write(0, index, header[index]) |
Row and column counting start from 0 therefore 0 is column A or row 1.
The index starts from the first column and takes the first element from the list, then the second column, and the second element.

Now, we must do the same with the remaining CSV elements.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
row_numer_male = 0 row_numer_female = 0 for row in csvreader: if row[3] == 'Male': row_numer_male += 1 for index in range(len(header)): worksheet1.write(row_numer_male, index, row[index]) elif row[3] == 'Female': row_numer_female += 1 for index in range(len(header)): worksheet2.write(row_numer_female, index, row[index]) |
The code checks each element in the fourth column of the CSV file, if it’s Male, the element is placed inside the first worksheet, if it’s Female, then into the second one.
The result for males:

And for females:

This is the full code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import csv import xlsxwriter with open('writers.csv', 'w', newline='') as file: writer = csv.writer(file) writer.writerow(["#", "Name", "Book", "Gender"]) writer.writerow([1, "Agatha Christie", "Murder on the Orient Express", "Female"]) writer.writerow([2, "J. K. Rowling", "Harry Potter", "Female"]) writer.writerow([3, "J. R. R. Tolkien", "Lord of the Rings", "Male"]) writer.writerow([4, "Stephen King", "The Shining", "Male"]) writer.writerow([5, "Danielle Steel", "Invisible", "Female"]) writer.writerow([6, "William Shakespeare", "Hamlet", "Male"]) file = open("writers.csv") csvreader = csv.reader(file) header = next(csvreader) workbook = xlsxwriter.Workbook('writers.xlsx') worksheet1 = workbook.add_worksheet('Male') worksheet2 = workbook.add_worksheet('Female') for index in range(len(header)): worksheet1.write(0, index, header[index]) worksheet2.write(0, index, header[index]) row_numer_male = 0 row_numer_female = 0 for row in csvreader: if row[3] == 'Male': row_numer_male += 1 for index in range(len(header)): worksheet1.write(row_numer_male, index, row[index]) elif row[3] == 'Female': row_numer_female += 1 for index in range(len(header)): worksheet2.write(row_numer_female, index, row[index]) file.close() workbook.close() |
Convert multiple CSV files to Excel sheets
We can take a different approach. If we have multiple CSV files inside a directory, we can convert each of them into an Excel worksheet named after this file.
We can modify the previous code to create two CSV files, one for female and the other one for male writers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
with open('female_writers.csv', 'w', newline='') as file: writer = csv.writer(file) writer.writerow(["#", "Name", "Book", "Gender"]) writer.writerow([1, "Agatha Christie", "Murder on the Orient Express", "Female"]) writer.writerow([2, "J. K. Rowling", "Harry Potter", "Female"]) writer.writerow([5, "Danielle Steel", "Invisible", "Female"]) with open('male_writers.csv', 'w', newline='') as file: writer = csv.writer(file) writer.writerow(["#", "Name", "Book", "Gender"]) writer.writerow([3, "J. R. R. Tolkien", "Lord of the Rings", "Male"]) writer.writerow([4, "Stephen King", "The Shining", "Male"]) writer.writerow([6, "William Shakespeare", "Hamlet", "Male"]) |
Next, let’s read the CSV files.
There are a few ways we can use to get all the files with a certain extension; using the glob module is one of them.
|
1 2 3 4 5 6 7 |
import glob import os files = glob.glob(r'C:\path\*csv') for file_path in files: print(file) |
The code above gets all the CSV files from the directory and prints them to the console.
What we need to do now, is to create an Excel file and use CSV files names as worksheet names. We also need to copy the contents of each CSV file into each sheet. The following code does just that.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import glob import os import csv import xlsxwriter files = glob.glob(r'C:\path\*csv') workbook = xlsxwriter.Workbook('writers.xlsx') row_numer = 0 for file_path in files: file = open(file_path) csvreader = csv.reader(file) file_name = os.path.basename(file_path) file_no_ext = os.path.splitext(file_name)[0] worksheet1 = workbook.add_worksheet(file_no_ext) row_numer = 0 for row in csvreader: for index in range(len(row)): worksheet1.write(row_numer, index, row[index]) row_numer += 1 file.close() workbook.close() |
The os.path.basename function strips the full file path and assigns only a name to the file_name variable. Next, this name (with) extension is split into the file name and file extension, where the name path is assigned to file_no_ext.
Each worksheet is named using this variable.