The pandas DataFrame or Series can be filtered based on substring using the following two functions.
- pandas.Series.str.contains(<args>) function or
- pandas.DataFrame.query(<args>)
Let’s discuss the two functions briefly and then work on some examples.
pandas.Series.str.contains()
These functions checks if a given substring is contained in pandas.Series. The function has the following syntax:
pandas.Series.str.contains(pattern, case=True, flags=0, na=None, regex=True)
Where
- pattern – is the sequence we are looking for in the pandas.Series,
- case – determines if the search is case-sensitive or not,
- flags – flags to pass through to the re module if the pattern is a regular expression.
- na – fills missing values when filtering, and
- regex – determines if the pattern is treated as a regular expression or a literal string sequence.
pandas.DataFrame.query(<args>)
This function works just like the pandas.Series.str.contains, but the parameters issued for the search are passed as a string. The function queries the columns of a DataFrame with a boolean string expression. Here is the syntax
pandas.DataFrame.query(expression, inplace=False)
Where:
- expression – is the query string, and
- inplace – determines if the pandas DataFrame is modified or a copy is returned.
Examples
In our examples, we will work with tips_data.csv file with the following contents
total_bill,tip,gender,smoker,day,time,size 16.99,1.01,Female,No,Sun,Dinner,2 10.34,1.66,1,No,Sun,Dinner, 16.93,3.07,0,,Sat,Dinner,3 27.2,4.0,Male,No,Thur,Lunch,4 10.07,1.83,Female,No,Thur,Lunch,1 28.97,3.0,Male,Yes,Fri,Dinner,2
The CSV file contains seven columns and six rows. The objective is to load the file using pandas and filter the resulting pandas DataFrame based on some criteria.
Let’s load the CSV file as a DataFrame, df. We will use this DataFrame for all the examples we will work on.
|
1 2 3 |
import pandas as pd # Looading the data from CSV file using pandas.reaad_csv(). df = pd.read_csv("tips_data.csv") |
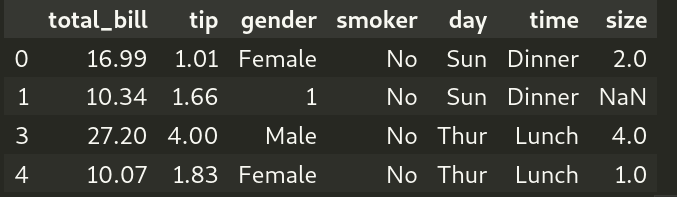
Example 1: Filter DataFrame for rows that do not contain the given substring
First, let’s look at how to filter rows with a given substring. In the code snippet below, we are filtering the DataFrame, df, for all the rows with gender==”Male”.
|
1 2 3 |
filter_condition = df["gender"].str.contains("Male") df_exclude_male = df[filter_condition] df_exclude_male |
Output (formatted for better viewing):

To do the opposite, we need to negate the filtering condition. These can be achieved in three different ways:
|
1 |
df_exclude_male = df[~df["gender"].str.contains("Male")] |
Or
|
1 |
df_exclude_male = df[df["gender"].str.contains("Male")==False] |
Or
|
1 2 |
df_exclude_male = df[df["gender"].str.contains("Male")==0] peint(df_exlude_male) |
Output (formatted for better viewing):
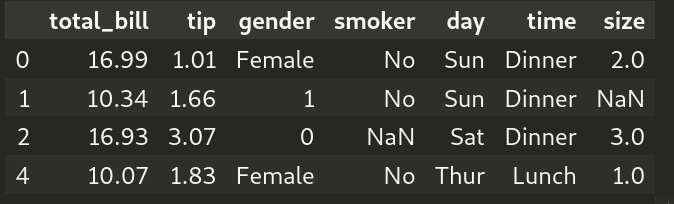
Example 2: Filter DataFrame using multiple substrings
Suppose we want to exclude all rows with gender equal to “Male” or “Female“. In that case, we can utilize the regex character “|” which stands for “Either or” (you can read more on https://docs.python.org/3/library/re.html ), that is,
|
1 2 |
df_exc_mf = df[~df["gender"].str.contains('Male|Female')] print(df_exc_mf) |
Output (formatted for better view):

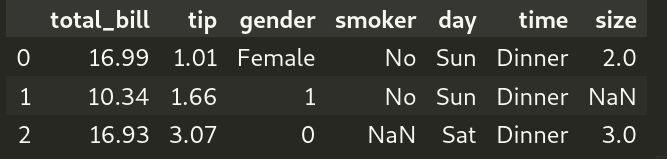
Example 3: Unleashing the power of regex
Provided that regex is set to True (by default, it is) on pandas.Series.str.contains(), we can use regular expressions in our pattern. For example, if we want to get rows with day starting with S, then we issue the pattern “^S” (^ means “starts with” in regex).
|
1 2 |
df_day_startswith = df[df['day'].str.contains("^S")==True] print(df_day_startswith) |
Output (formatted for better view):
Another one is to filter the DataFrame to get all the rows that do not end with “r” on the column time, for example.
|
1 2 |
df_exclude_endswith = df[~df['time'].str.contains("r$")] df_exclude_endswith |
Output (formatted for better view):

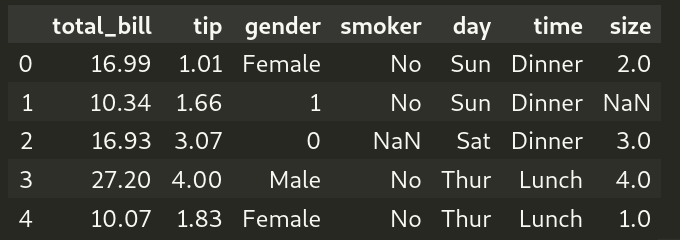
Example 4: Dealing with missing values
The smoker column of df contains a missing value. If we search for a substring in that column, we will end with the following error.
|
1 |
df[df["smoker"].str.contains('No')] |
Output:
ValueError: Cannot mask with non-boolean array containing NA / NaN values
To solve this problem, we need to set the parameter na=False on pandas.Series.str.contains(), that is,
|
1 2 |
df_smoker_missing = df[df["smoker"].str.contains('No', na=True)] print(df_smoker_missing) |
Output (formatted for better view):
Example 5: Filtering non-string columns
The pandas.Series.str.contains() cannot work on non-string columns unless we convert them into string types. For example,
|
1 |
df[df['total_bill'].str.contains("10.07|16.93")] |
Output:
AttributeError: Can only use .str accessor with string values!
|
1 2 3 |
#converting the column to string type solved the problem df_tostring = df[~df['total_bill'].astype(str).str.contains("10.07|16.93")] df_tostring |
Output (formatted for better view):
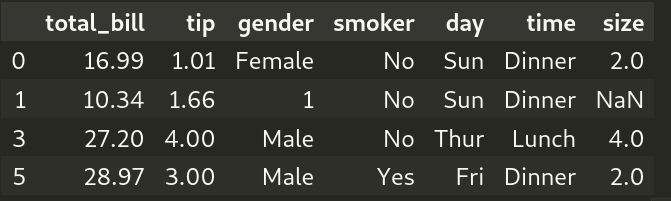
Example 6: Filtering based on Multiple columns
The following example shows how to filter a DataFrame based on multiple columns using pandas.Series.str.contains() and pandas.DataFrame.query()
|
1 2 3 4 |
condition1 = df["gender"].str.contains("male|1", case=False) condition2 = df["smoker"].str.contains("No", na=False) condition3 = df["day"].str.contains("Sun|Thur", na=False) df_multiple_filter = df.loc[((condition1) &(condition2) & (condition3))] |
Or
|
1 2 3 4 |
df_multiple_filter = df.query('gender.str.contains("Male|1", case=False).values &\ smoker.str.contains("No", na=False).values &\ day.str.contains("Sun|Thur", na=False).values') print(df_multiple_filters) |
Output (formatted for better view):