What are Unicode Characters?
Character encoding, in simple terms, is a process of translating characters into integers or sequences of bits. Any character we can write has a corresponding representation in Unicode that is universally accepted across different languages.
This representation is called a code point or Unicode character. Many encoding standards can be used to represent string characters as Unicode characters and vice versa (you can see the standard encoding allowed in Python here).
In Python3, UTF-8 encoding, and decoding are implemented by default.
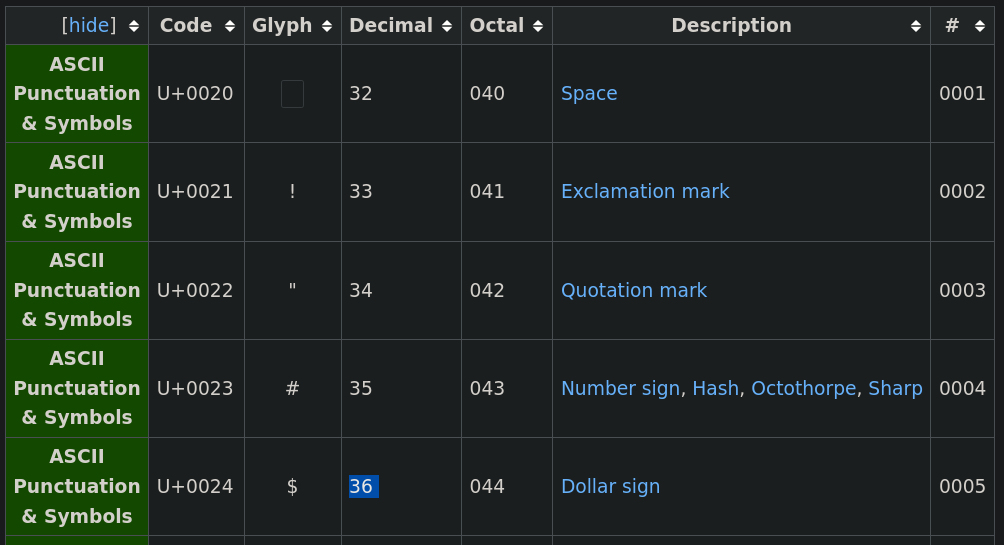
There are two inbuilt functions in Python that we can use to convert string characters into Unicode, and vice versa (Matching Decimal and Glyph columns in Figure 1 above), namely,
- ord(char) – Given a string representing one Unicode character, char, ord() returns an integer representing the Unicode code point of that character.
- chr(i) – return a string representing a character whose Unicode code point is the integer i.
For example:
|
1 2 |
print("Tilde Unicode: ", ord("~")) print("Character for Unicode 35: ", chr(35)) |
Output:
Tilder Unicode: 126 Character for Unicode 35: #
The tilde symbol (~) is represented by the integer 126 in Unicode, and the symbol # is the number 35 (see Figure 1).
Two ways to Represent Unicode Characters in Python
Both Python 3 and Python 2 can have Unicode characters literally in a string. For Python 2, “u” must precede the Unicode string, for example, u”I ♥ u”, whereas, for Python 3, that is not necessary, i.e., you can write “I ♥ u”.
We can also use escape sequences (“\u”) to represent Unicode characters (Matches Code and Glyph columns in Figure 1 above). You can do this in two ways:
- \u4_digits_hex
Use this method for a character whose code point can be expressed in 4 hexadecimal decimals. If fewer than 4 digits are needed, add zeros in front.
- \U8_digits_hex
Use this if more than 4 hexadecimal decimals are needed. Again, if less than 8 digits are required, you can pad the string with zeros at the front to make 8 digits.
For example (see Figure 1). If you are running Python 2, remember to precede the Unicode string with “u”.
|
1 2 3 |
print("\U00008364") print("\u0067") print("\u0024") |
Output:
荤 g $
Now that we have some background on Unicode characters let’s move on to the article’s main focus – to remove Unicode characters from Python strings.
Removing Unicode Characters from Python Strings
We will discuss three ways in this article. But before that, let’s mention ASCII encoding. It is the most common character encoding format with 128 unique characters, including 56 alphabets (a-z and A-Z), numbers (0-9), some other special characters and symbols, and control codes.
This definition applies only to Python; otherwise, ASCII has been “extended” to contain 256 unique values. For most English words and sentences, ASCII encoding is sufficient.
|
1 2 3 4 5 6 7 8 |
case1 = "keep\u0420it\u043egoing.\u0441Never\u0441give\u0438up.\u044f$" case2 = "keepРitоgoing.сNeverсgiveиup.я$" print(case1==case2) print(case1.encode("unicode_escape")) print(case2.encode("unicode_escape")) print(case1) print(case1.encode("unicode_escape").decode("utf-8")) |
Output:
True b'keep\\u0420it\\u043egoing.\\u0441Never\\u0441give\\u0438up.\\u044f$' b'keep\\u0420it\\u043egoing.\\u0441Never\\u0441give\\u0438up.\\u044f$' keepРitоgoing.сNeverсgiveиup.я$ keep\u0420it\u043egoing.\u0441Never\u0441give\u0438up.\u044f$
The two strings case1 and case2 are equivalent (that is why case1==case2 returns True). That is because we just wrote the Unicode characters in case1 as glyphs in case2.
The encoding “unicode_escape” is a Python-specific encoding system that allows us to prevent strings from being decoded automatically with UTF-8 encoding (Notice that in print(case1), Python decoded the Unicode characters automatically).
Lastly, encoded data is in bytes (the output is b formatted). To convert bytes into Python strings, we can decode the bytes. In our case, we used the “utf-8” encoding system because it is the most common.
Note: Data should be decoded with the same system used to encode it. The above example assumes that the bytes object is in UTF-8 (the default in Python and the most common encoding, so we are safe to presume here).
Let’s now see how we can remove Unicode characters in Python String
Method 1. Using ASCII encoding
In this case, we want the string to be ASCII compliant.
|
1 2 3 4 5 |
str1 = "keep\u0420it\u043egoing.\u0441Never\u0441give\u0438up.\u044f" #the string below str2 is equivalent to str1. You can use any. #str2 = "keepРitоgoing.сNeverсgiveиup.я" a = str1.encode(encoding="ascii", errors="ignore") print(a) |
Output:
b'keepitgoing.Nevergiveup.'
In this example, string str1 is encoded by ASCII, and the errors are just ignored. That is to say, if a glyph or Unicode cannot be converted into one of the 128-length ASCII characters, it is skipped.
You can also choose to replace the non-ASCII characters as follows:
|
1 2 3 |
str2 = "keepРitоgoing.сNeverсgiveиup.я" a = str2.encode(encoding="ascii", errors="replace").decode().replace("?", " ") print(a) |
Output:
keep it going. Never give up.
In the code snippet, any non-ASCII character is replaced (with “?” by default) through encoding, then we decode the bytes data into a string, and lastly replace “?” with whitespace.
Method2: Using regular expressions (re) package
Python re module matching is Unicode by default. In the code below, using re.UNICODE flag or not will yield the same result.
|
1 2 3 4 5 6 |
import re case1 = "keep\u0420it\u043egoing.\u0441Never\u0441give\u0438up.\u044f" case2 = "keepРitоgoing.сNeverсgiveиup.я" print(re.findall(r'[\x00-\x7F]+', case1)) print(re.findall(r'[\x00-\x7F]+', case2, flags=re.UNICODE)) |
Output:
['keep', 'it', 'going.', 'Never', 'give', 'up.'] ['keep', 'it', 'going.', 'Never', 'give', 'up.']
The pattern r'[\x00-\x7F]+’ captures all ASCII Unicode characters. Just like saying ‘a-z’ means all alphabets between a and z, the pattern r'[\x00-\x7F]+’ means all the Unicodes between \x00 and \x7F, which are all ASCII.
We can also use the module re.sub() function to substitute non-ASCII characters with whitespace (or any other character).
|
1 2 3 4 |
import re case1 = "keep\u0420it\u043egoing.\u0441Never\u0441give\u0438up.\u044f" print(re.sub(r'[^\x00-\x7F]+',' ',case1)) |
Output:
keep it going. Never give up.
Using ^ in the pattern string negates the pattern requirements. In this case, it means we need all non-ASCII characters replaced.
Method3: Using ord() function
As stated earlier, there are 128 characters in ASCII encoding, and in fact, they are indexed 0 through 127 in the ordinal list; in that case, any character having an ord value above 128 is non-ASCII.
|
1 2 3 4 5 |
import re case1 = "keep\u0420it\u043egoing.\u0441Never\u0441give\u0438up.\u044f" a = "".join([i if ord(i)<128 else " " for i in case1 ]) print(a) |
Output:
keep it going. Never give up.
If ord(char)<128, that is an ASCII character, so we keep it; otherwise, we replace the character with whitespace ( ” “). We then join lists of characters using the join() function.