This article involves the conversion of a CSV file into a UTF-8 encoding. This encoding supports over 1.1 million characters using 1 to 4-byte code units. This means the UTF-8 system can encode most of the characters you know in any language.
UTF-8 is the default encoding for Linux, Windows, and macOS. That means these OS systems will always support storing data in this encoding.
This article is for you if you need to convert a CSV file encoded in a different format into UTF-8.
Checking the Encoding Used in a CSV File
This can be done using the chardet package, which can be installed using pip by running the following command:
pip install chardet
The following code shows how to check the encoding used when writing a CSV.
|
1 2 3 4 5 6 7 |
import chardet # pip3 install chardet with open("employees2.csv", "rb") as file: # Read the csv file in binary and check the encoding result = chardet.detect(file.read()) encoding = result["encoding"] print(encoding) |
Output:
UTF-16
The UTF-16 encoded employees2.csv file used in the code above is shown below (the file is opened on Notepad):
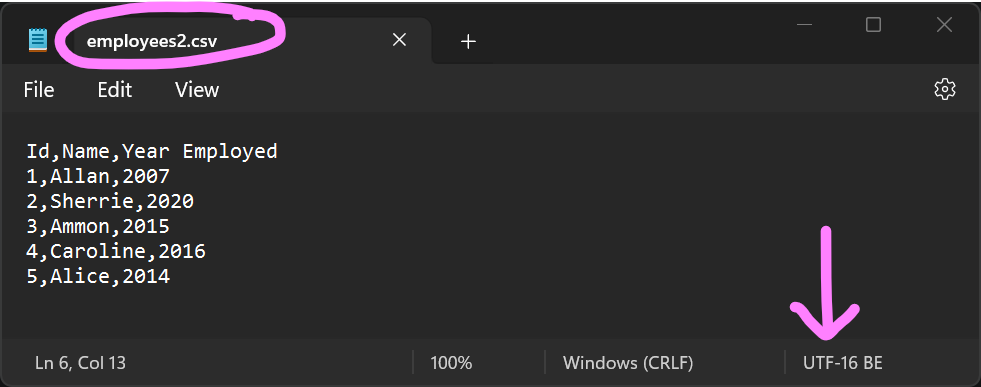
Converting CSV into UTF-8
This Section discusses three methods to convert a CSV file into UTF-8 encoding.
Method 1: Using csv and codecs packages
This Method achieves the purpose in two steps – read the input CSV with the valid encoding and use codecs to convert the CSV into UTF-8 encoding.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import csv import codecs def Convert_CSV_To_UTF8(input_path, output_path): # Read the CSV file with open(input_path, "r", encoding="utf-16") as infile: data = csv.reader(infile) rows = list(data) # Write the contents into another CSV file with UTF-8 encoding with codecs.open(output_path, "w", encoding="utf-8", errors="ignore") as outfile: writer = csv.writer(outfile) writer.writerows(rows) # Call the Convert_CSV_To_UTF8 to convert input CSV input_csv = "employees2.csv" output_csv = "output.csv" Convert_CSV_To_UTF8(input_csv, output_csv) |
Output:
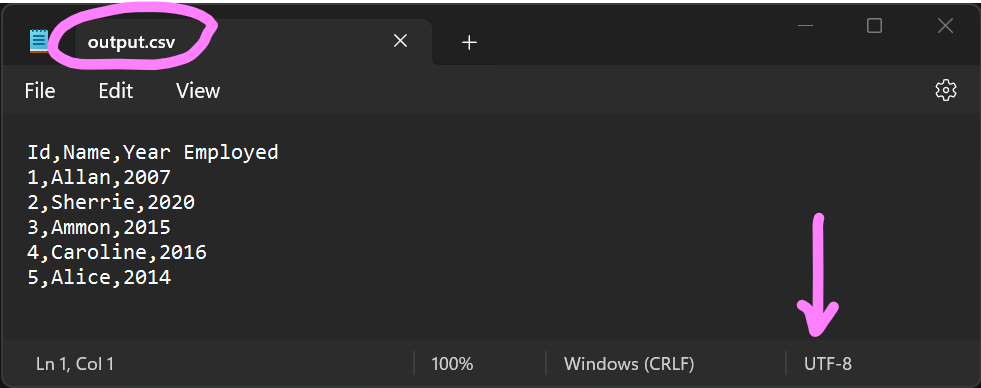
Note: we passed the errors=” ignore” argument into codecs.open() function in the code above. This ensures that encoding errors encountered when converting CSV into UTF-8 are skipped. This is convenient to ensure that the conversion works, but data that can’t be converted will be lost.
Method 2: Using pandas
Like Method 1, this Method works in two steps – read the input CSV and write the output into another CSV – UTF-8 encoded.
|
1 2 3 |
import pandas as pd df = pd.read_csv("employees2.csv", encoding="utf-16") df.to_csv("output1.csv", encoding="utf-8") |
Output:
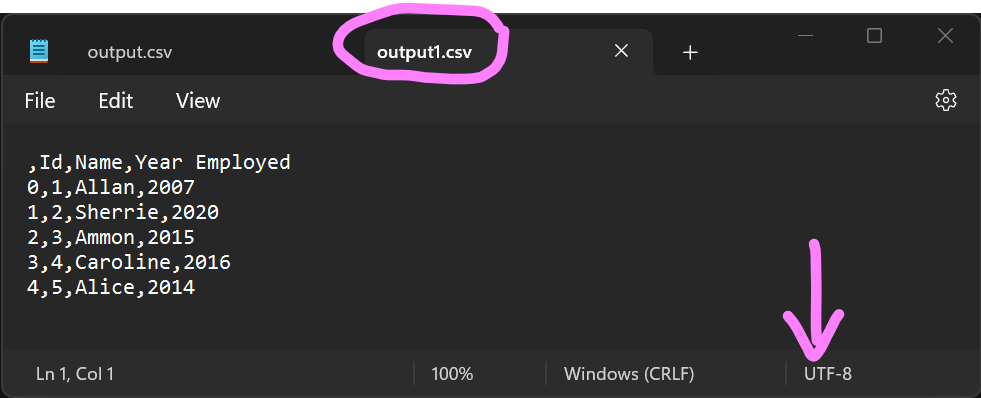
Like in Method 1, we also passed the errors=”ignore” argument into pd.DataFrame.to_csv() to skip encoding errors.
Note that pandas.read_csv() fails if valid encoding used in the input file is not provided. You can check for the encoding using the code provided at the start of the article.
Method 3: Using codecs and shutil modules
In this Method, we use codecs to open input and output objects with the required encodings and use shutil to copy the contents of the input into output.
|
1 2 3 4 5 6 7 8 9 |
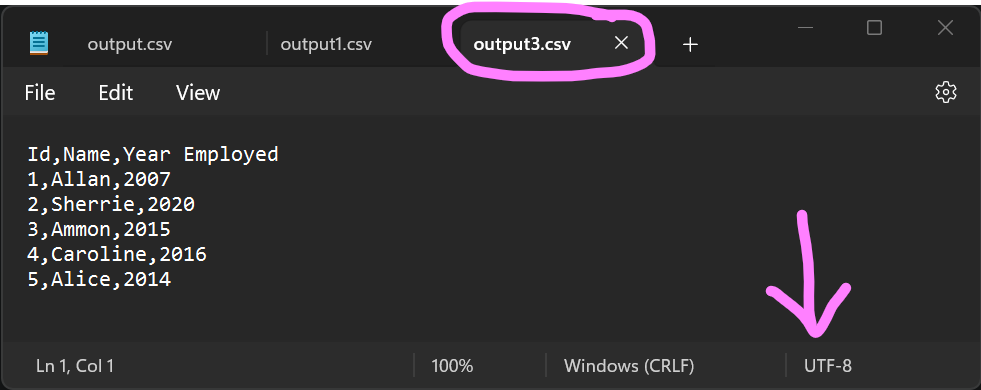
import codecs, shutil # Read input CSV with the proper encoding into infile object. with codecs.open("employees2.csv", mode="r", encoding="utf-16") as infile: # Create outfile in write mode with UTF-8 encoding. with codecs.open( "output3.csv", mode="w", encoding="utf-8", errors="ignore" ) as outfile: # Copy the contents of infile object to outfile object. shutil.copyfileobj(infile, outfile) |
Output:
Conclusion
This post discussed three methods for converting CSV into UTF-8 – the first method using csv package, the second using pandas, and the last using codecs and shutil.
All methods allow you to pass the errors=” ignore” argument if you want to skip encoding errors, that is, ignore characters that cannot be encoded with UTF-8.