To convert an Excel spreadsheet into JSON, first, you have to import the necessary modules: one for reading an Excel file and the second one for converting this data into the JSON format.
For this task, let’s use a simple table with countries. Each of them has a name, capital, and official language.
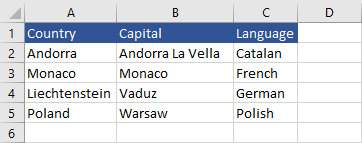
First, let’s install a module that will let us read Excel files: openpyxl.
|
1 2 |
from openpyxl import load_workbook from openpyxl.utils import get_column_letter |
The first line allows us to load a file with an Excel workbook. The second one will retrieve a column letter from a column number.
You also have to import JSON, so we can dump the data to the output or a file.
|
1 |
import json |
The next lines are going to return the last non-empty column and row inside our spreadsheet.
|
1 2 |
last_column = len(list(ws.columns)) last_row = len(list(ws.rows)) |
The next part is a nested loop. We have to use it because we have to travel through rows and columns inside a worksheet.
|
1 2 3 4 5 6 7 |
for row in range(1, last_row + 1): my_dict = {} for column in range(1, last_column + 1): column_letter = get_column_letter(column) if row > 1: my_dict[ws[column_letter + str(1)].value] = ws[column_letter + str(row)].value my_list.append(my_dict) |
The range starts from 1 (0 by default) because the first row and column have the number 1, not 0. In this case, we also have to add 1 to the second range parameter.
For each row, there is the new dictionary my_dict created.
Next, we have to check whether the row number is at least 2, otherwise, the header would be also written as a value.
For each column in a row (in other words, for each cell in the row) the value is added to a dictionary.
Before moving to the new row, the dictionary is appended to the end of the list, creating a list of dictionaries.
In the end, the data is dumped and written into a file.
|
1 2 3 |
data = json.dumps(my_list, sort_keys=True, indent=4) with open('D:/data.json', 'w', encoding='utf-8') as f: f.write(data) |
The whole code looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from openpyxl import load_workbook from openpyxl.utils import get_column_letter import json wb = load_workbook(filename='D:/countries.xlsx') ws = wb.active my_list = [] last_column = len(list(ws.columns)) last_row = len(list(ws.rows)) for row in range(1, last_row + 1): my_dict = {} for column in range(1, last_column + 1): column_letter = get_column_letter(column) if row > 1: my_dict[ws[column_letter + str(1)].value] = ws[column_letter + str(row)].value my_list.append(my_dict) data = json.dumps(my_list, sort_keys=True, indent=4) with open('D:/data.json', 'w', encoding='utf-8') as f: f.write(data) |
If you open the data.json file in a text editor, you are going to have Excel data written as a JSON file.
[
{},
{
"Capital": "Andorra La Vella",
"Country": "Andorra",
"Language": "Catalan"
},
{
"Capital": "Monaco",
"Country": "Monaco",
"Language": "French"
},
{
"Capital": "Vaduz",
"Country": "Liechtenstein",
"Language": "German"
},
{
"Capital": "Warsaw",
"Country": "Poland",
"Language": "Polish"
}
]