The data in a Python dictionary can be converted to an Excel spreadsheet using the pandas library. Pandas is a powerful library for data analysis and manipulation with Python, and it’s a great tool to use with dictionaries.
Example
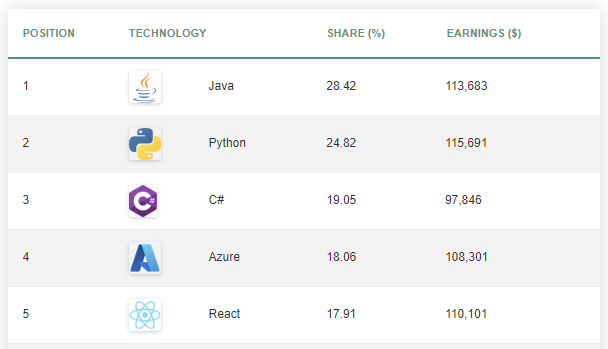
The first thing we need to do is to find data for our example. Let’s get it from the codeigo index, which presents the popularity and earnings of different technologies and programming languages. Let’s take the first five rows of data.
|
1 2 3 4 5 6 7 8 9 10 11 |
import pandas as pd tech = { 'Position': [1, 2, 3, 4, 5], 'Language': ['Java', 'Python', 'C#', 'Azure', 'React'], 'Share': [28.42, 24.82, 19.05, 18.06, 17.91], 'Earnings': [113683, 115691, 97846, 108301, 110101] } df = pd.DataFrame(tech) df.to_excel('data.xlsx') |
After creating the tech dictionary, we are going to put it inside DataFrame as an argument.
DataFrame is one of the main components of the Pandas library which allows users to work with tabular data stored in a DataFrame object.
As the last line, we are saving the DataFrame object as the Excel workbook called “data.xlsx”.
If you open the file, you are going to get the following result:
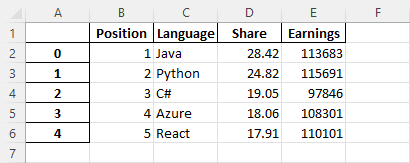
Removing index
The problem with this result is that in this example, we have an index in column A that starts from 0 and a position in column B that starts from 1.
You can also index entirely from the DataFrame before converting it to an Excel spreadsheet.
The only thing you have to change is to set the second parameter index to False.
|
1 |
df.to_excel('data.xlsx', index=False) |
The result looks like this:
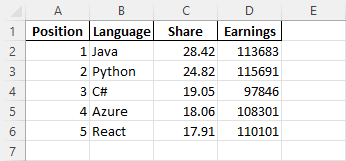
Giving index a name
Let’s modify this example, so the index is back and starts from 1. We are also going to change the name, so instead of a blank cell, there is the name “Position”.
We also have to remove “Position” from the dictionary.
The new example looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
import pandas as pd tech = { 'Language': ['Java', 'Python', 'C#', 'Azure', 'React'], 'Share': [28.42, 24.82, 19.05, 18.06, 17.91], 'Earnings': [113683, 115691, 97846, 108301, 110101] } df = pd.DataFrame(tech, index=[1, 2, 3, 4, 5]) df.rename_axis('Position', inplace=True) df.to_excel('data.xlsx') |
This is the result:
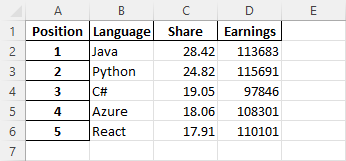
The second argument of the DataFrame is an index. It sets all indexes from 1 to 5.
The df.rename_axis(‘Position’, inplace=True) fragment changes the index name in cell A1 to “Position”.
Nested dictionaries with pandas
If you want to create more complicated examples, you can use nested dictionaries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
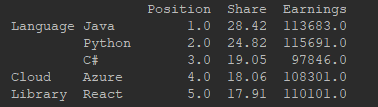
import pandas as pd tech = { 'Language': { 'Java': [1, 28.42, 113683], 'Python': [2, 24.82, 115691], 'C#': [3, 19.05, 97846] }, 'Cloud': { 'Azure': [4, 18.06, 108301] }, 'Library': { 'React': [5, 17.91, 110101] }, } dict_of_dataframes = {k: pd.DataFrame(v, index=['Position', 'Share', 'Earnings']).T for k, v in tech.items()} df = pd.concat(dict_of_dataframes) print(df) df.to_excel('data.xlsx') |
This code results in the following output:
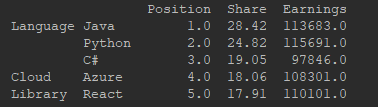
When you open the Excel file, you are going to see this result:
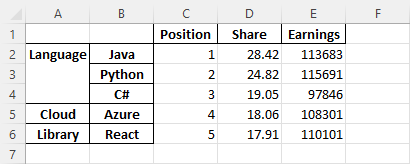
Explanation of the code
A lot of things are going on here. Let me explain this example. To make this easier to understand, let’s remove indexes and transposition for now.
There is the for loop that creates a dictionary of 3 DataFrames.
|
1 |
{k: pd.DataFrame(v) for k, v in tech.items()} |
tech.items() method returns a view object that contains the key-value pairs of the dictionary:
|
1 2 3 |
'Language', {'Java': [1, 28.42, 113683], 'Python': [2, 24.82, 115691], 'C#': [3, 19.05, 97846]} 'Cloud', {'Azure': [4, 18.06, 108301]} 'Library', {'React': [5, 17.91, 110101]} |
Instead of taking all three key-value pairs, let’s take the first one – “Language”.
In this case:
k = “Language”
v = {‘Java’: [1, 28.42, 113683], ‘Python’: [2, 24.82, 115691], ‘C#’: [3, 19.05, 97846]}
|
1 2 3 |
language_dataframe = {'Language': pd.DataFrame(tech['Language'])} df = pd.concat(language_dataframe) print(df) |
The concat function concatenates pandas object. If you run the code, the result is going to look like this:
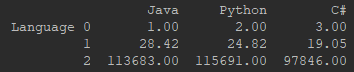
Now, we need to switch indexes with language names: Java, Python, and C#.
We can’t transpose the DataFrame (df.T) because it will switch language names with “Language” and indexes.
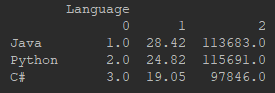
What we need to do is to transform DataFrame before concatenating “Language”.
|
1 2 3 |
language_dataframe = {'Language': pd.DataFrame(tech['Language']).T} df = pd.concat(language_dataframe) print(df) |
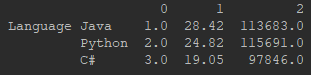
Change the first line to replace the default indexes with the new ones:
|
1 |
language_dataframe = {'Language': pd.DataFrame(tech['Language'], index=['Position', 'Share', 'Earnings']).T} |
We can’t merge multiple dictionaries using the concat function. First, you have to convert them into DataFrames using concat and then again merge them into one DataFrame:
|
1 2 3 4 5 6 7 |
language_dataframe = {'Language': pd.DataFrame(tech['Language'], index=['Position', 'Share', 'Earnings']).T} cloud_dataframe = {'Cloud': pd.DataFrame(tech['Cloud'], index=['Position', 'Share', 'Earnings']).T} library_dataframe = {'Library': pd.DataFrame(tech['Library'], index=['Position', 'Share', 'Earnings']).T} language_dataframe = pd.concat(language_dataframe) cloud_dataframe = pd.concat(cloud_dataframe) library_dataframe = pd.concat(library_dataframe) df = pd.concat([language_dataframe, cloud_dataframe, library_dataframe]) |
The result is going to be the same as before: